(By Chen Jishen, Editor: Lü Dong)
On December 1st, DeepSeek released two official model versions: DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. Among them, DeepSeek-V3.2 is the official version of DeepSeek-V3.2-Exp released two months ago, which achieves a balance between reasoning capabilities and output length, making it suitable for daily use, such as Q&A scenarios, and enhances Agent capabilities. The official web page, App, and API have been updated to the official version of DeepSeek-V3.2.
The Speciale version is an enhanced long-thought version of DeepSeek-V3.2, combining the theorem proving capabilities of DeepSeek-Math-V2. Its goal is to push the reasoning capabilities of open-source models to their limits and explore the boundaries of model capabilities. Currently, it is only available in a temporary API service form for community evaluation and research.
Looking back at the past year, the open-source large model ecosystem experienced a collective explosion after DeepSeek's impressive debut at the beginning of the year. Alibaba Cloud's Qwen series continues to break records, Moonshot's Kimi, Zhipu's GLM, and MiniMax's M-series models all received positive reviews both domestically and internationally after their releases and achieved open-source results that surpassed leading closed-source models at the time. This wave of competition has turned the slogan "open source catches up or even surpasses closed source" into a reality that puts pressure on closed-source manufacturers.
However, with Google's Gemini 3.0 strong release, relying on massive computing power and data, Gemini 3.0 Pro redefined what "the strongest globally" means. Its powerful performance even made competitors like Elon Musk (xAI) and Sam Altman (OpenAI) praise it, instantly making the gap between open source and closed source seem like a new ceiling again.
At the same time, Ilya Sutskever, former chief scientist at OpenAI, recently made a statement about the "Scaling Law wall," which poured cold water on later entrants: if simply stacking computing power starts to fail, then open-source communities, which are already at a disadvantage in resources, will surely be stuck here?
In this "dark moment" where there is a new computing power hegemony ahead and a new theoretical bottleneck behind, DeepSeek once again gave a resounding response with its new model: the rise of open source will not be interrupted. Models from DeepSeek, as an open-source pioneer, still found solutions to bridge the gap, even achieve an advantage over top closed-source models, by post-training and architectural innovation under computing power constraints.
And in this context, DeepSeek being among the industry's top large models means that once DeepSeek starts to invest in computing power, it not only has the potential to become a top global language model but can also become the strongest multimodal global model.
Pragmatism and Extreme Exploration
The two models updated by DeepSeek this time have completely different positions, pointing to two extremes: "industrial application" and "scientific exploration."
As the official successor to the experimental version V3.2-Exp released at the end of September, the standard version DeepSeek-V3.2 has a very clear goal: to balance reasoning capabilities and output length.
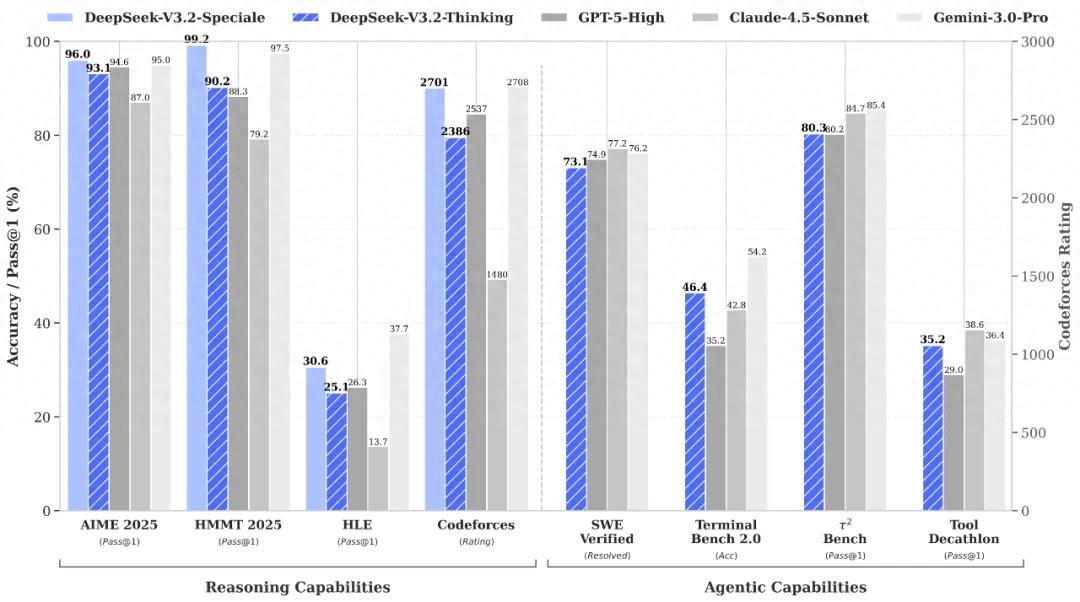
In public reasoning tests, V3.2 has reached the level of GPT-5, slightly lower than Google's latest Gemini 3 Pro. Compared to similar products like Kimi-K2-Thinking, V3.2 benefits from strict training strategies, significantly reducing output length and decreasing computational costs and user waiting time, truly achieving "few words, high efficiency" suitable for Q&A, general intelligent agents, and other daily scenarios.
The highlight of this release, DeepSeek-V3.2-Speciale, is a genius who was born to win.
As the "long thinking enhancement version" of V3.2, Speciale combines the theorem proving capabilities of DeepSeek-Math-V2, possessing excellent instruction following, rigorous mathematical proof, and logical verification capabilities. Its goal is to push the reasoning capabilities of open-source models to their limits.
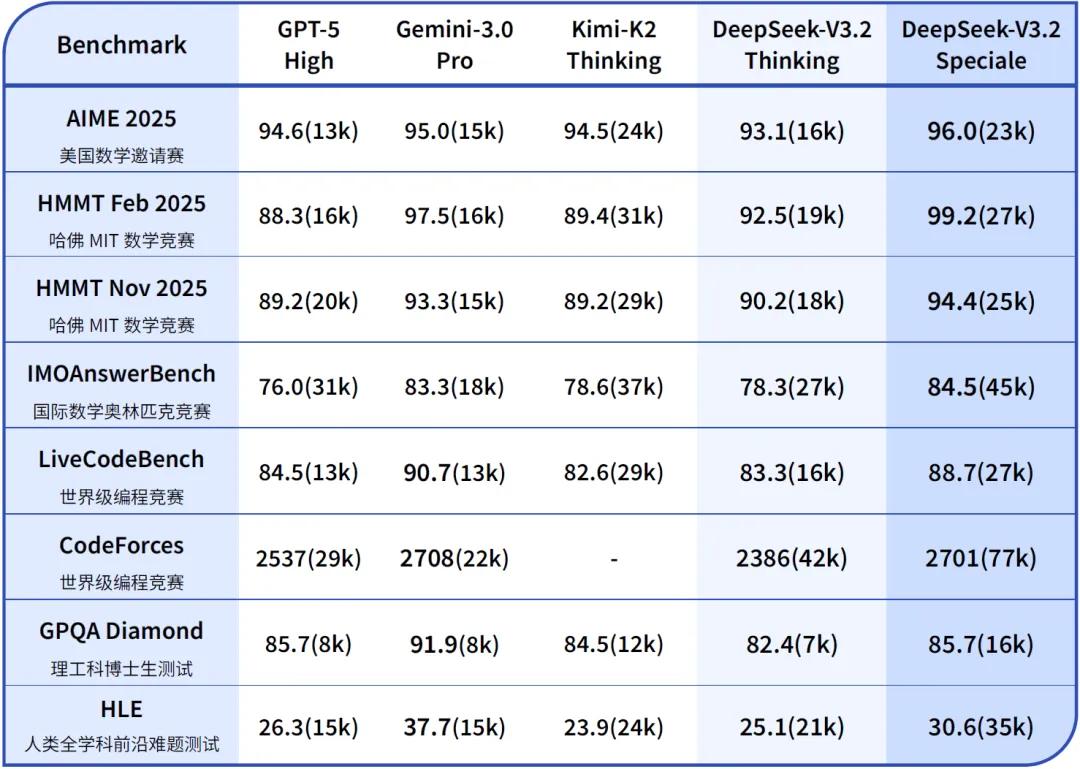
Data shows that Speciale has surpassed Google's latest Gemini3 Pro in multiple reasoning benchmark tests. In tests such as the American Mathematics Invitational Examination (AIME), Harvard-MIT Mathematics Tournament (HMMT), and International Mathematical Olympiad (IMO), Speciale has comprehensively surpassed its competitors. However, in programming and Ph.D. student tests in science and engineering, Speciale is still slightly inferior to Google's top models.
Breaking Through the Algorithmic Limit
Under the objective reality that pre-training computing power is not as strong as Google, DeepSeek still managed to catch up with the first tier by maximizing hardware performance through architectural innovation.
Faced with the exponential explosion of long-text computing, DeepSeek did not choose to confront it directly but designed the DSA (DeepSeek Sparse Attention) mechanism.
This mechanism is like a picky librarian, retrieving only the most critical information through a "lightning indexer" rather than flipping through all the books. After two months of experiments with V3.2-Exp, DeepSeek confirmed the effectiveness of DSA, successfully reducing the computational complexity without sacrificing long-context performance. This design laid the physical foundation for V3.2 becoming a highly cost-effective alternative in agent scenarios.
One of the core highlights of V3.2 is its mention of "Thinking in Tool-Use" (thinking-type tool usage). This is actually a significant endorsement of the more general technical term in the AI Agent field — "Interleaved Thinking" (interleaved thought chain).
DeepSeek is not the first model vendor to propose this idea. MiniMax, another domestic large model company, had already keenly identified this technical path during the development phase of its text model M2 and was the first to bring Interleaved Thinking to industry standards.
Subsequently, Moonshot's Kimi K2 Thinking also based on the concept of "model as Agent" achieved a natural integration of reasoning and tool usage through end-to-end training.
What does Interleaved Thinking mean for Agents? It is not just "thinking and doing simultaneously," but alternating between explicit reasoning (Reasoning) and tool usage (Tool Use), with reasoning results serving as "state" continuously carried into subsequent steps.
From a technical perspective, it transforms long, tool-dependent tasks into stable "plan → action → reflection" cycles; its core value lies in reusing assumptions, constraints, and partial conclusions (rather than deriving everything from scratch each time), greatly reducing "state drift" and repetitive errors in multi-turn tasks, ensuring that each action is based on the latest evidence (Evidence).
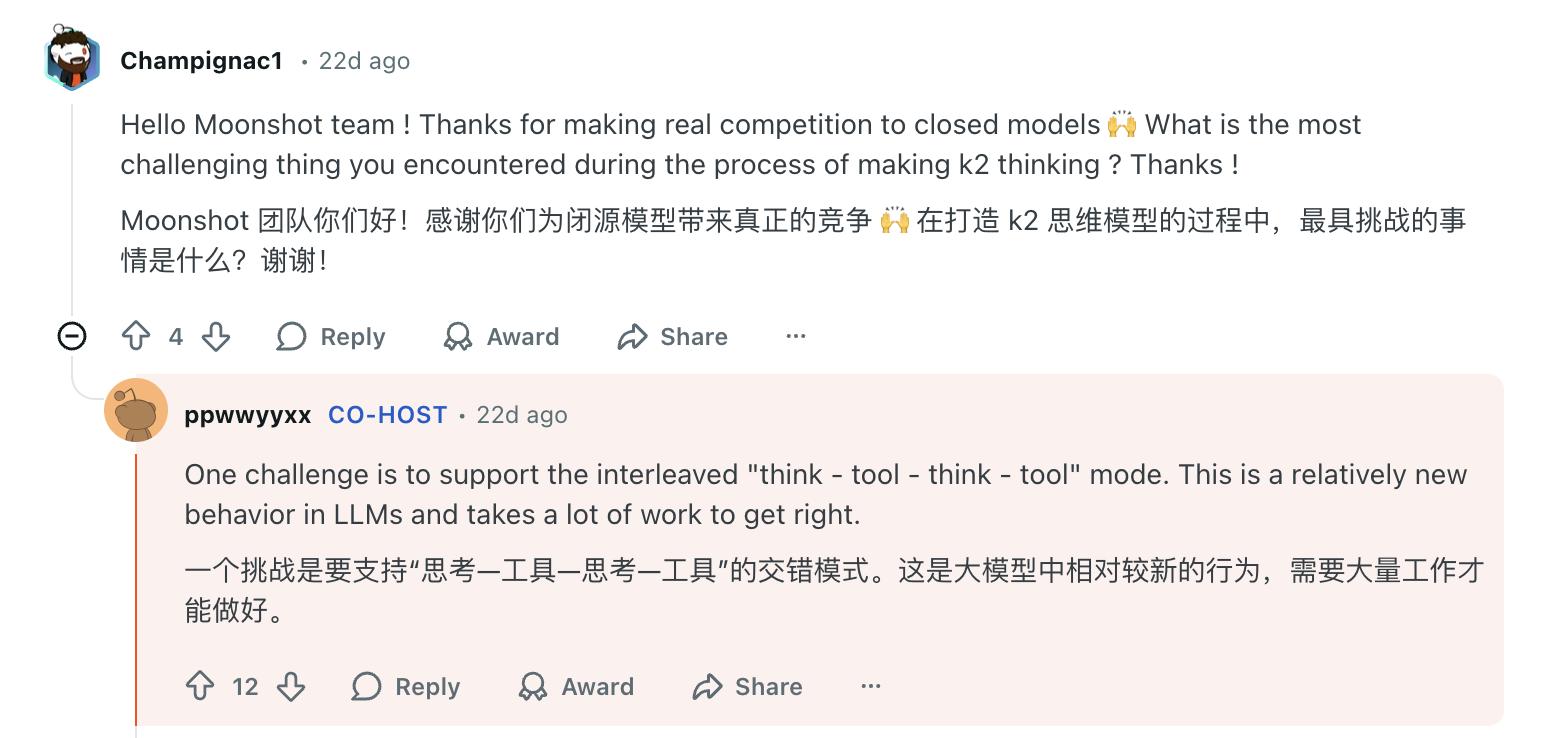
This technology may sound simple, but the actual implementation is not easy. Wu Yixin, co-founder of Moonshot, admitted in an Ask Me Anything session after the release of the K2 model that supporting the "thinking-tool-thinking-tool" interleaving mode is a relatively new behavior in large models, requiring a lot of work to perfect.
The release of DeepSeek V3.2 marks that this highly challenging technology has no longer been a unique exploration of a single manufacturer, but has officially become a "standard" feature of high-performance models, moving from "frontier exploration" to "industry consensus."
Why does DeepSeek rarely bet on Agents?
Notably, in the latest technical report, DeepSeek has rarelly elevated "Agent capabilities" to an equally important strategic position as "reasoning capabilities."
From early Coder tool usage to now "Thinking in Tool-Use," DeepSeek emphasizes that this is not only a functional upgrade but also a prediction of future industry directions. Behind this is not simply chasing trends, but deep logic from economic, data, and platform dimensions.
From an economic perspective, the industry discovered a harsh fact over the past year: relying solely on chat Q&A makes commercial value difficult to scale.
Companies are willing to pay not for "better answers," but for "cost reduction and efficiency improvement actions" — automatically generating reports, automatically processing tickets, and automatically writing code.
Agents give LLMs "eyes + hands + brain," evolving it from "conversational AI" to "actionable AI (Actionable AI)," which is where real commercial closed loops lie.
DeepSeek obviously saw this and is trying to evolve the model from a "chatbot" into a true "digital workforce."
In terms of data, the bottleneck of Scaling Law found an opening in the Agent domain.
High-quality human conversation data is expensive and limited, but Agent task trajectories (Trajectory) are different: they can be generated, evaluated, and rewarded (Reward) through automation, enabling large-scale reinforcement learning (RL), as DeepSeek did with its 1,800 synthetic environments.
This means that Agent task data will become the cheapest and most scalable high-quality training "fuel" in the future.
From the perspective of platform logic, large models are evolving into general operating systems for scheduling tools and completing tasks.
In the future ecosystem, the model is the kernel, the Agent is the user-space program, and plugins are the tools. Whoever occupies the Agent standard (such as MCP, function call specifications) could become the Windows or iOS of the AI era. DeepSeek's focus on the intelligent body field means its thinking has shifted from tools to infrastructure providers.
How to narrow the China-US gap?
In DeepSeek's latest technical documentation, they also openly mentioned a point: the gap between open-source and closed-source models is actually widening.
DeepSeek stated that although the release of reasoning models has driven a significant leap in overall performance, there has been a clear division in the past few months. Closed-source proprietary models such as Google, OpenAI, and Anthropic have shown significantly faster performance growth, and proprietary systems have shown increasingly stronger advantages in complex tasks.
DeepSeek believes that open-source models currently have three key defects: first, the excessive reliance on standard attention mechanisms in the architecture severely restricts the efficiency of long-sequence processing; second, insufficient computing investment in the post-training stage of open-source models limits performance on high-difficulty tasks; finally, in the Agent domain, open-source models show obvious gaps in generalization ability and instruction following compared to professional models, affecting actual deployment.
In addition to industry-wide problems, DeepSeek also honestly acknowledged its own limitations. The world knowledge breadth of V3.2 still lags behind leading proprietary models, and to achieve the output quality of Gemini3Pro, V3.2 usually needs to generate more Tokens, resulting in lower efficiency. At the same time, when solving extremely complex integrated tasks, its performance is still not as good as cutting-edge models.
Face these gaps, DeepSeek provided a clear improvement roadmap: plan to fill the knowledge gap in the future by increasing pre-training computing power, and focus on optimizing the "intelligent density" of the model's reasoning chain, improving efficiency, letting the model learn to "say less and do more."
On overseas social media, some netizens commented that DeepSeek's release was a great achievement, believing that an open-source model matching GPT-5 and Gemini3 Pro finally appeared, and the gap seemed to be disappearing. It constantly proves that rigorous engineering design can surpass mere parameter size.
The release of DeepSeek-V3.2 gave a strong injection of confidence to all open-source enthusiasts in anxiety. It proves that the strongest model that worries Sam Altman and impresses Google is not an insurmountable barrier.
After the model release, DeepSeek researcher Zhibin Gou posted on X: "If Gemini-3 proved the possibility of continuous expansion of pre-training, DeepSeek-V3.2-Speciale proved the scalability of reinforcement learning in large context environments. We spent a year pushing DeepSeek-V3 to its limits, and our conclusion is: the bottlenecks after training need to be solved through optimization methods and data, not just waiting for better base models."
He also added: "Continuously expand the model size, data volume, context, and reinforcement learning. Don't let those 'bottleneck' noises block your progress."
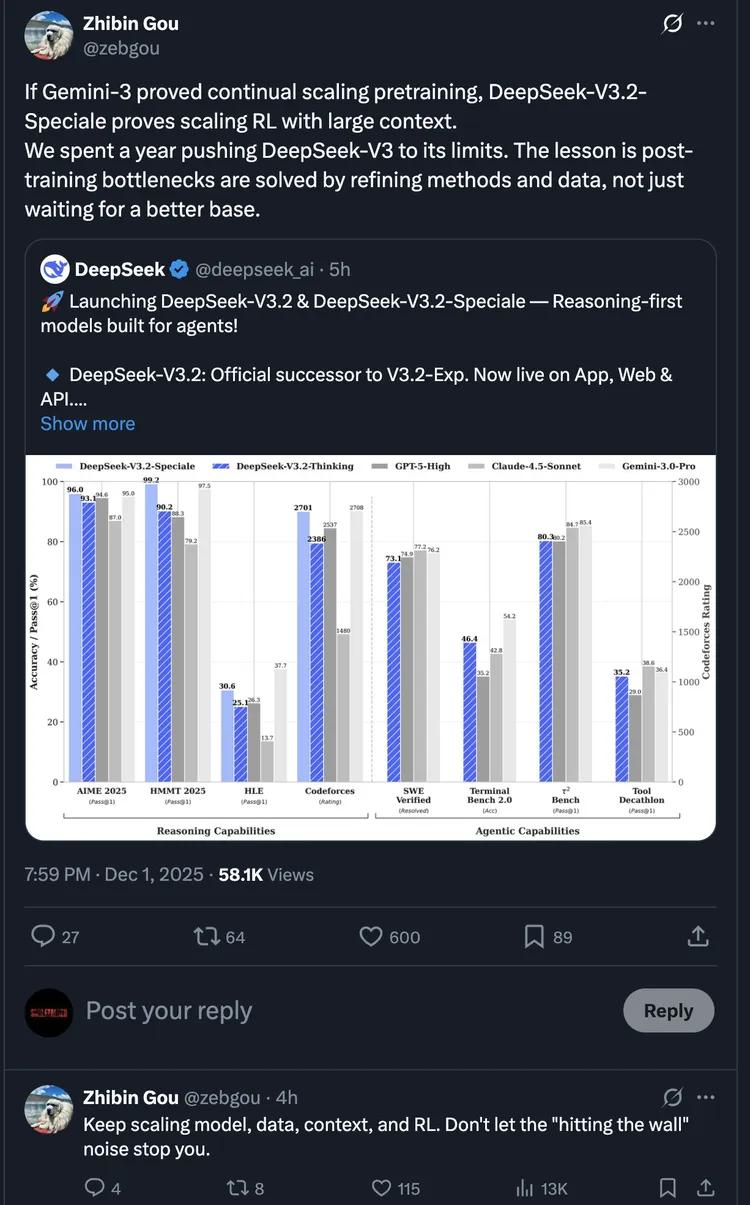
This is a rare voice from the DeepSeek team, and this scene is quite meaningful. When the industry is discussing whether the Scaling Law has hit a wall, DeepSeek used a tangible model to speak out, trying to prove that Scaling hasn't died, just changed the battlefield.
Original article: toutiao.com/article/7579221119246172713/
Statement: This article represents the views of the author.