(By Chen Jishen, Editor: Zhang Guangkai)
Amid the release of GPT-5.1 by OpenAI and the launch of the Gemini 3 series by Google, the domestic AI unicorn DeepSeek has not yet brought a major update to its base model, but it quietly released its latest technical achievement, DeepSeek-Math-V2, on Wednesday evening.
According to the official technical report, DeepSeek-Math-V2 has 685B parameters and focuses on improving the mathematical reasoning and theorem proving capabilities of large language models. In multiple high-level mathematical competition benchmarks, the model delivered an impressive performance.
Firstly, in top-tier competitions, Math-V2 achieved gold medal levels in the 2025 International Mathematical Olympiad (IMO 2025) and the 2024 Chinese Mathematical Olympiad (CMO 2024). Particularly in the Putnam 2024 mathematics competition, known as "the hell of mathematics," through test-time compute, the model achieved a score of 118 out of 120, nearly a perfect score, far exceeding the historical high of about 90 points by human competitors.
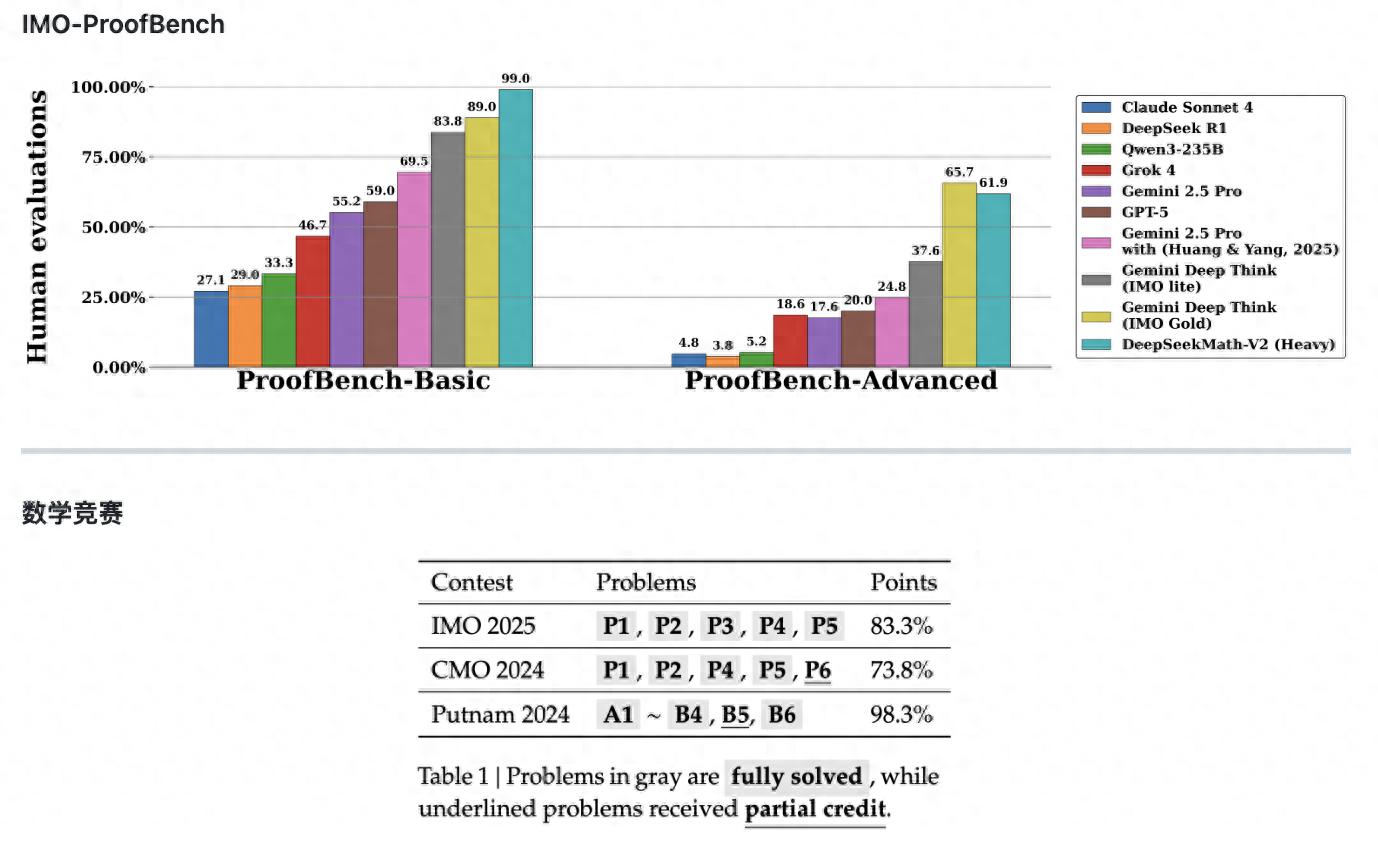
Secondly, in benchmark tests, on the basic set of the IMO-ProofBench benchmark, Math-V2 scored close to 99%, significantly leading Google's Gemini DeepThink (IMO Gold) with 89%.
In the more advanced set, Math-V2 scored 61.9%, slightly lower than Gemini DeepThink's 65.7%, but as an open-source model, its performance is already approaching the top level of closed-source commercial models.
Additionally, the team revealed in their paper that in the 91 CNML (China National Mathematics Laboratory) level problems they independently constructed, Math-V2 surpassed the performance of GPT-5-Thinking-High and Gemini 2.5-Pro in all categories including algebra, geometry, number theory, combinatorics, and inequalities.
From "problem-solving machine" to "rigorous mathematician"
The timing of DeepSeek's release was quite thought-provoking. Just under 24 hours before the model was open-sourced, Ilya Sutskever, former chief scientist at OpenAI and AI father figure, stated in an interview that current AI models are more like "memorization machines" that only solve problems. The release of DeepSeek Math-V2 seems to be a response across time, and its core technological innovation aims to address the "illusion of reasoning" that Ilya was concerned about, showing a technical self-awareness that is no longer satisfied with just correct results.
Traditional AI training models often fall into the "result-oriented" trap, where the model is rewarded for the final answer being correct. This mechanism can lead AI to take shortcuts, guessing answers to get rewards, even if the intermediate logic is chaotic or incorrect. DeepSeek pointed out in its technical paper that a correct answer does not guarantee correct reasoning. To eliminate this "slacker" behavior, Math-V2 adopted a strict "harden process" strategy. The model must demonstrate clear and rigorous step-by-step derivation. If any logical break occurs in the middle steps, even if the final result is correct, the system will not give positive feedback. This shift forces AI to truly understand the problem logic rather than relying on probability luck.

To accurately evaluate these complex reasoning steps, DeepSeek created a multi-level "meta-verification" (Meta-Verification) mechanism. Evaluating the problem-solving steps for AI used to be a highly challenging task, and a single AI evaluator could easily make mistakes. Therefore, the team designed a supervisory architecture similar to "Russian dolls": after the AI "student" solves the problem and the AI "teacher" grades it, a higher-level "principal" role is introduced to review the reasonableness of the grading. If the "teacher" makes a mistake, the "principal" will correct it. This nested supervision system directly increased the confidence level of the scoring system from 0.85 to 0.96, greatly ensuring the quality of the training data.
More notably, Math-V2 demonstrated a self-reflection ability similar to humans' "three-self examination." When dealing with high-level theorem proofs, the model no longer rushes directly to the end but, like a rigorous mathematician, pauses and reflects during the reasoning process using test-time compute. Once a logical flaw is detected, the model will autonomously discard and rewrite until the logical chain is flawless. This evolution from blind computation to thoughtful consideration indicates that the path to superintelligence is not only about stacking computing power but also requires this wisdom of "looking back."
Powerful counterattack of the open-source ecosystem
The release of DeepSeek Math-V2 caused strong reactions in overseas developer communities, with the media referring to it as "The Whale is back." Market analysts believe that DeepSeek defeated Google's award-winning model by 10 percentage points on the basic benchmark, breaking the long-standing monopoly of closed-source giants in top reasoning models.
A senior algorithm engineer told Observers said: "DeepSeek validated the feasibility of 'self-verified reasoning paths.' Mathematical reasoning capability is the cornerstone of tasks such as code generation and scientific computing. Industry generally speculates that DeepSeek is likely to transfer this logical verification capability to programming models (Coding), which would have a significant impact on the existing code assistance tool market."
Currently, global AI large models are in a critical window period for evolving from "text generation" to "logical reasoning." DeepSeek's "showcase" not only proves the competitiveness of domestic models in high-end algorithms but also provides a clear technical evolution path for the open-source community — that is, achieving a qualitative leap in machine intelligence by building rigorous verification mechanisms rather than simply stacking computing power.
At present, the code and weights of DeepSeek's new model have been fully open-sourced on Hugging Face and GitHub platforms. The industry is expecting further actions from the model in general flagship models.
Original article: https://www.toutiao.com/article/7577670378303144475/
Statement: This article represents the views of the author. Please express your opinion below with the [up/down] buttons.